当我们新建一个网站后,总是希望它能够更多地出现在人们的视野中。那么将我们的网站添加进搜索引擎的搜索索引中去,就是一个很好的方式。
下面以Hugo和Google Search Console为例,进行具体的操作说明。
1 确保Hogo网站配置正确
Hugo是一个非常流行的开源静态网站生成器。它拥有出色的速度和非常大的灵活性。关于使用Hugo生成静态网站的操作流程,请看《Hugo快速入门》。
下面,我们先确保Hugo网站已为搜索引擎收录做好准备。
1.1 检查baseURL
搜索引擎爬虫会根据Hugo生成的静态网站的baseURL来确定网站地址。如果Hugo配置文件中的baseURL不正确或缺失,会导致爬虫找不到或误解网站结构。所以,我们首先要检查Hugo配置文件。
Hugo的配置文件分为toml与yaml两种类型,例如:config.toml或hugo.yaml。
1.1.1 config.toml
检查主配置文件config.toml,确保baseURL设置为生产环境域名,并且以斜杠“/”结尾。
# config.toml 示例
baseURL = 'https://nimblecode.tech/'
1.1.2 hugo.yaml
如果配置文件是hugo.yaml,则检查该文件。确保baseURL设置为生产环境域名,并且以斜杠“/”结尾。
# hugo.yaml示例
baseURL: 'https://nimblecode.tech/'
1.2 生成robots.txt
文件robots.txt告诉搜索引擎当前网站哪些页面可以抓取,哪些不能。Hugo可以自动生成一个基础的robots.txt文件。
在终端执行
hugo -D
命令后,可以在public文件夹内找到该文件。内容如下:
User-agent: *
Disallow:
Sitemap: https://nimblecode.tech/sitemap.xml
- 第一行说明所有的搜索引擎爬虫都可以爬取当前网站的内容;
- 第二行说明当前网站没有任何禁止爬取的内容;
- 第三行是可选的,说明站点地图文件(描述网站内容)的位置;方便搜索引擎爬虫爬取内容。
1.3 生成站点地图文件(sitemap.xml)
站点地图是向搜索引擎传递网站所有可索引页面的最佳方式。Hugo默认会自动生成一个站点地图文件,即sitemap.xml。
在终端执行
hugo -D
命令后,可以在public文件夹内找到该文件。
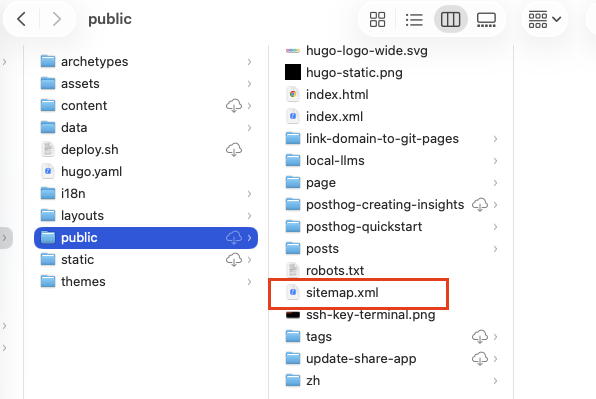
1.4 确保页面可见性
Hugo的文章必须是非草稿状态才能被部署到public/目录中。所以要确保文章的Front Matter中的draft字段设置为false。
---
# ... 其他元数据
draft: false
---
然后重新运行“hugo -D”命令来构建和部署。
2 配置Google Search Console
完成Hugo配置后,还需要引导Google搜索引擎来抓取网站页面。下面是在Google Search Console的操作步骤说明。
2.1 提交站点地图
打开Google Search Console网站,如下:
完成登陆后,就可以配置希望Google搜索引擎抓取的网域或者网址了。下图以nimblecode.tech网域做示例说明:
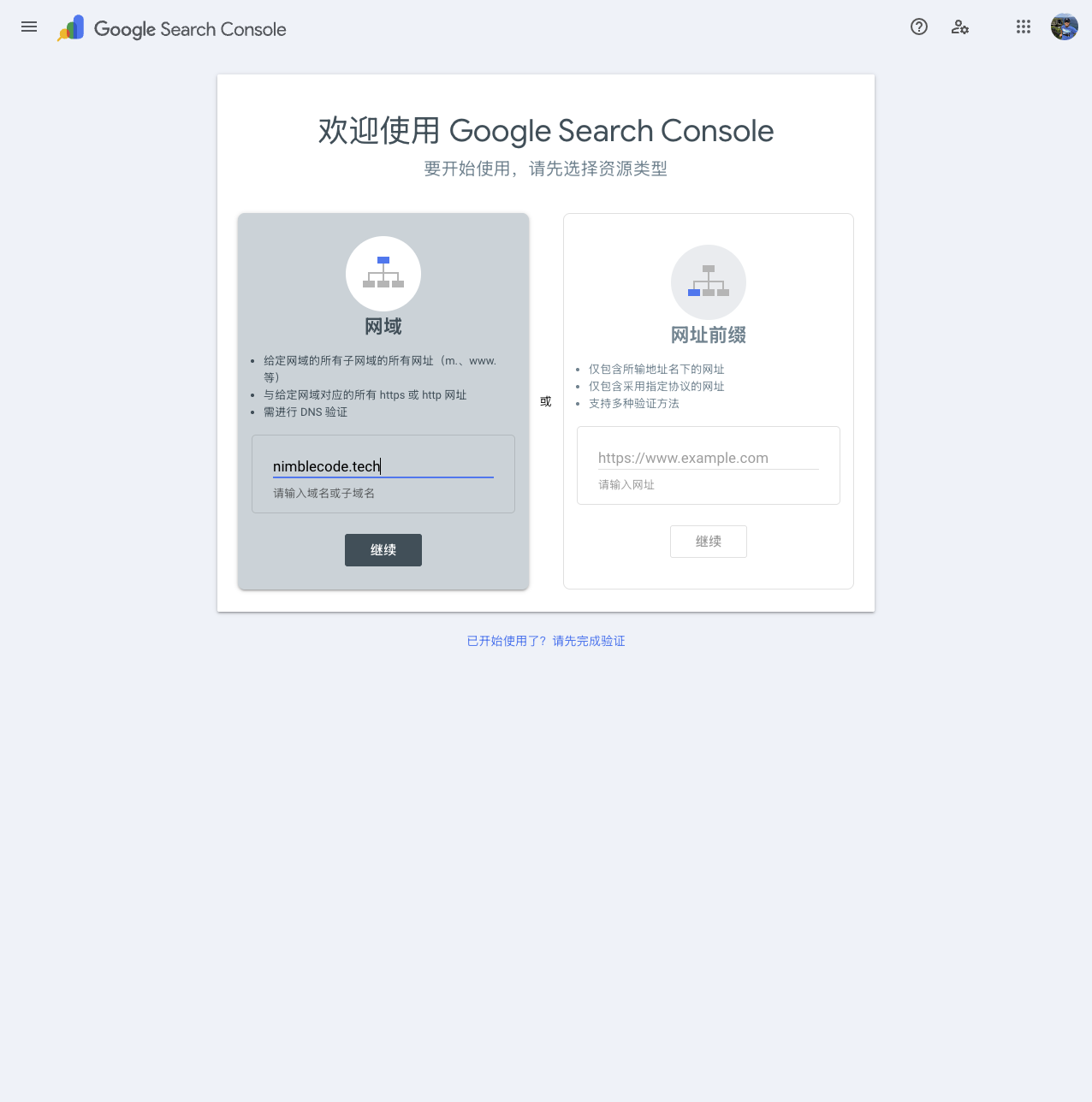
这个过程需要验证用户对指定网域/网址的所有权,一般需要1~3分钟。
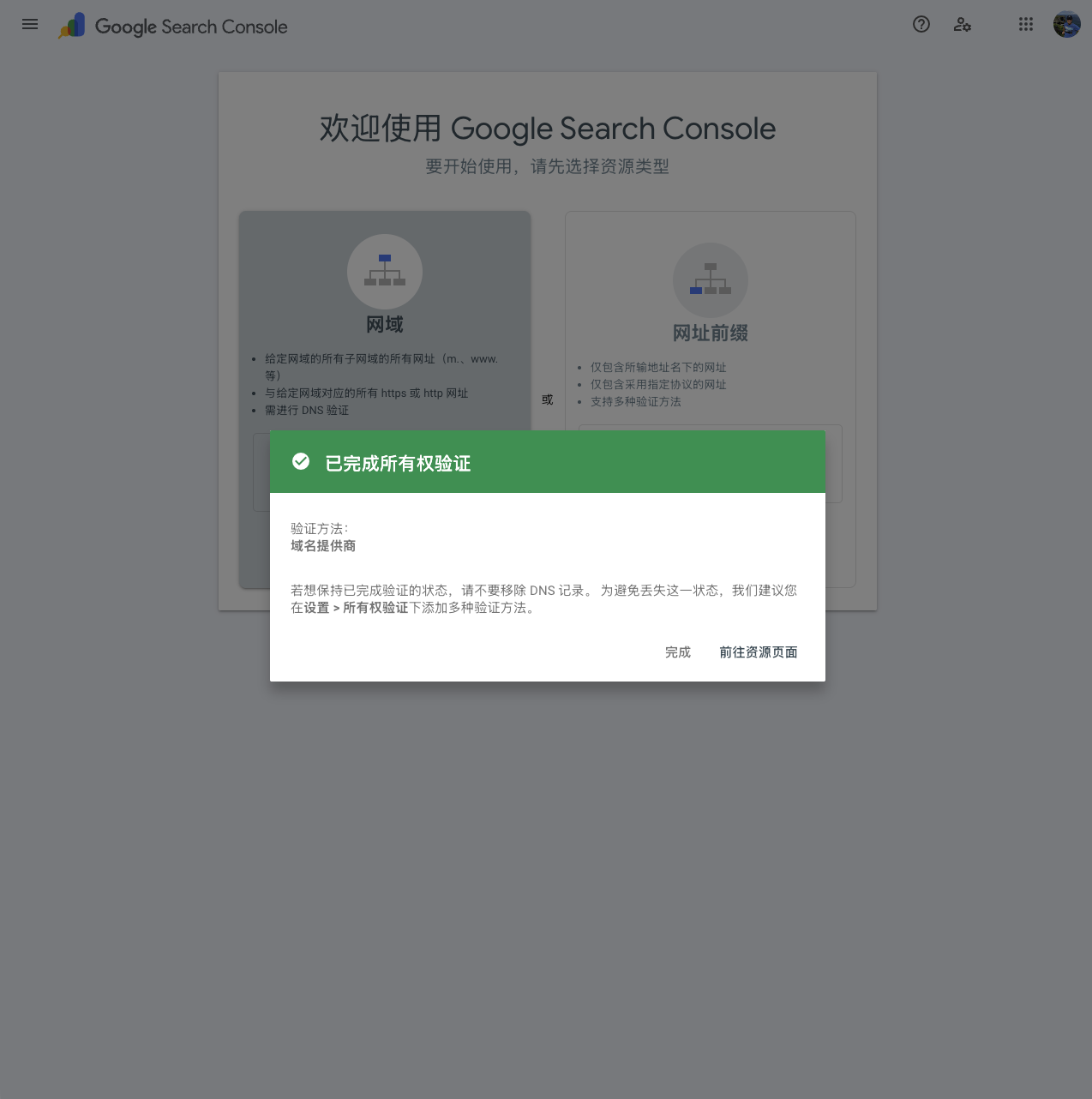
如果遇到问题导致失败,只需按要求做修改即可。
进入Google Search Console的控制台后,点击左侧“站点地图”菜单。然后“添加新的站点地图”地址,并点击“提交”即可。
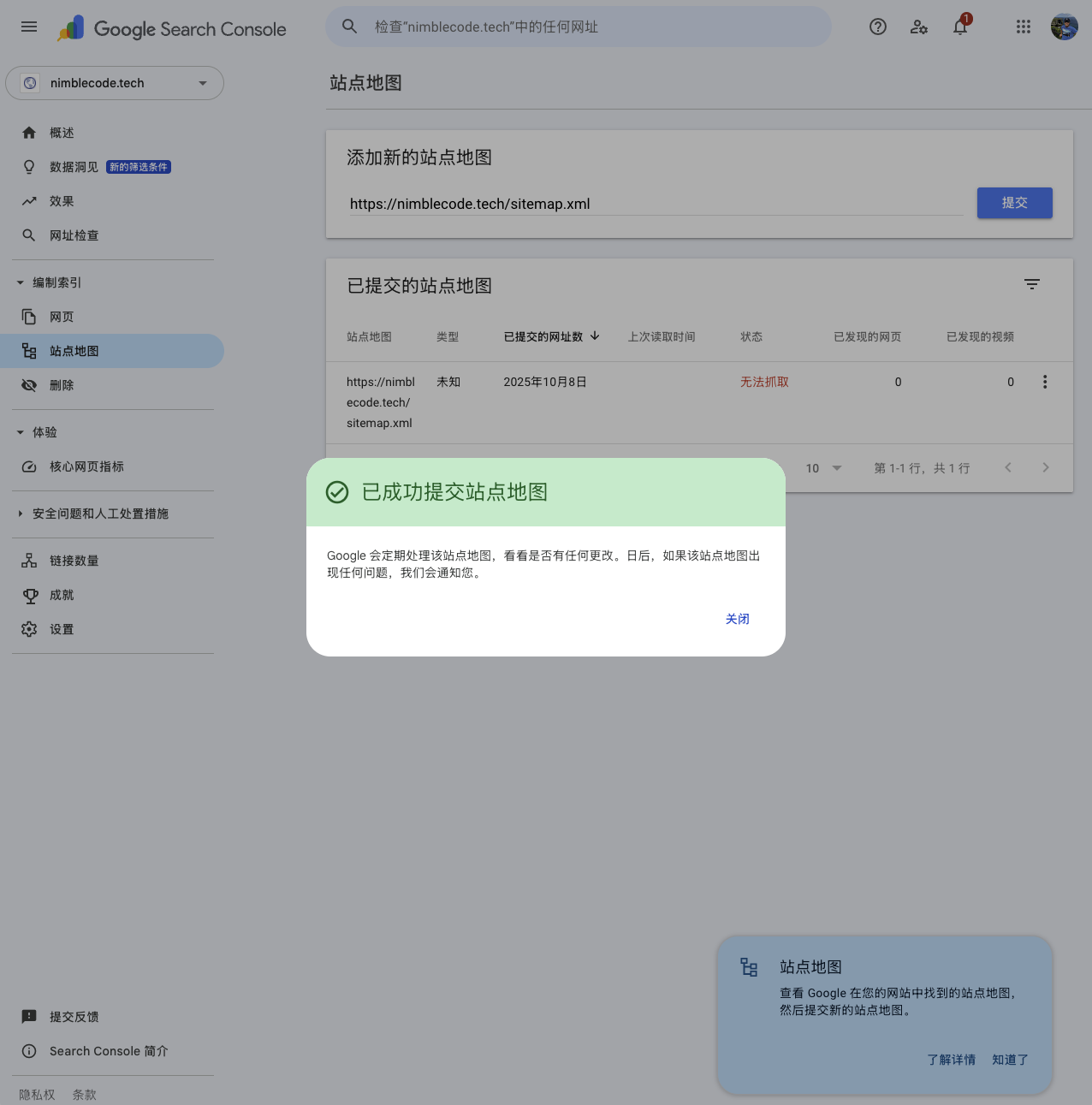
刚刚提交的站点地图,状态可能是“无法抓取”。这种情况不用太担心,因为Google搜索引擎需要排队处理站点内容。一般几个小时至3天内就会变更为“成功”状态。
至此,向Google Search Console提交站点地图的过程就完成了。搜索引擎此后会定期查看这个文件,并抓取其中的所有链接。
2.2 请求增加特定URL索引
除了提交站点地图,等待Google收录该站点所有页面外,还可以尝试让Google Search Console直接收录指定URL索引。
具体的步骤是先登陆Google Search Console,然后在顶部的搜索框(URL Inspection tool,网址检查工具)中输入网页的完整URL。例如
https://nimblecode.tech/posts/hugo-quick-start/
如果显示“网址尚未收录到Google”,点击“请求编入索引”即可。
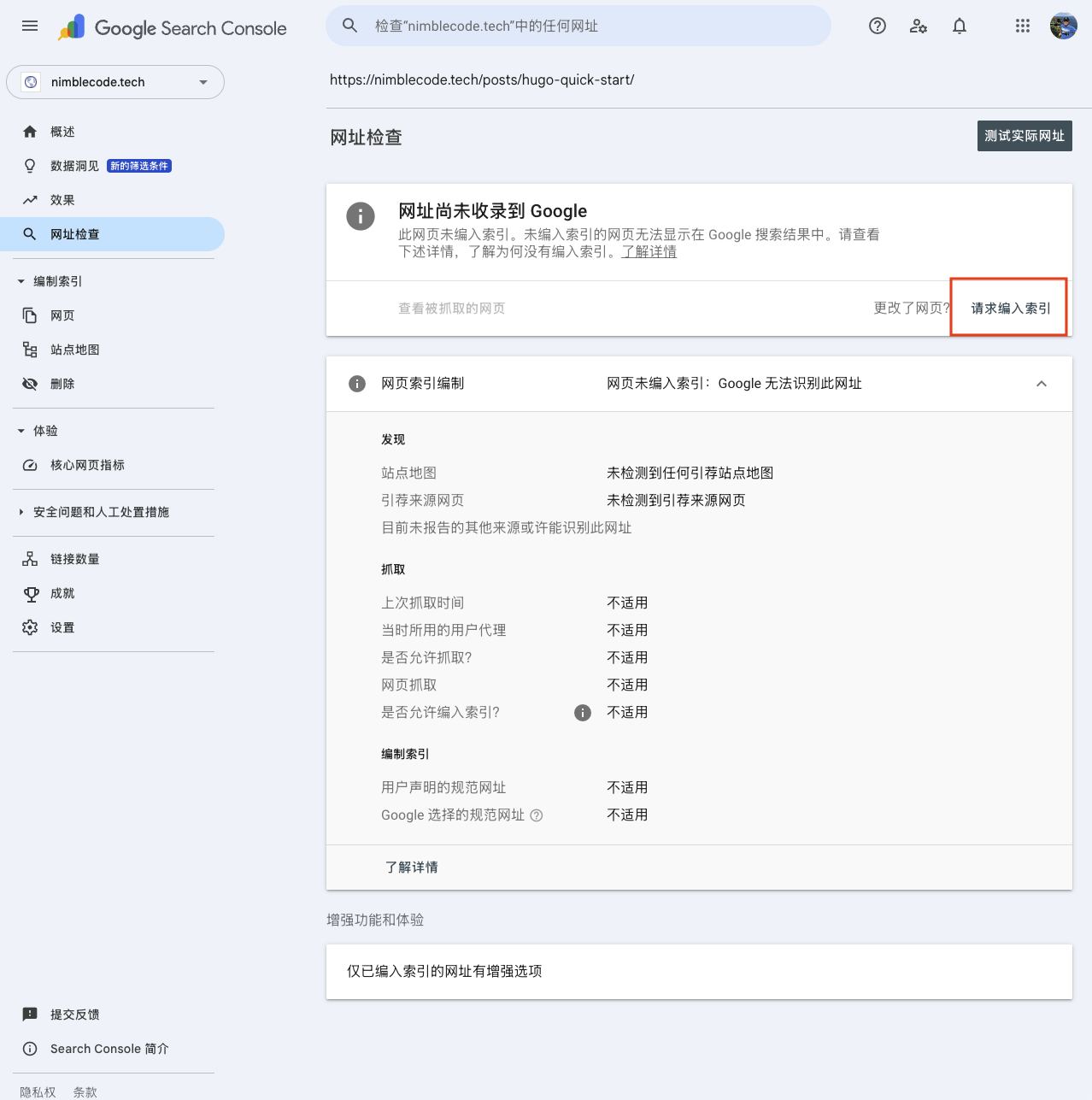

不过这种方式申请编入Google索引的生效时间不定,可能要等待较长时间。
2.3 添加新资源
如果需要同时管理多个网站,可以在左上角的网站列表中点击“添加资源”。
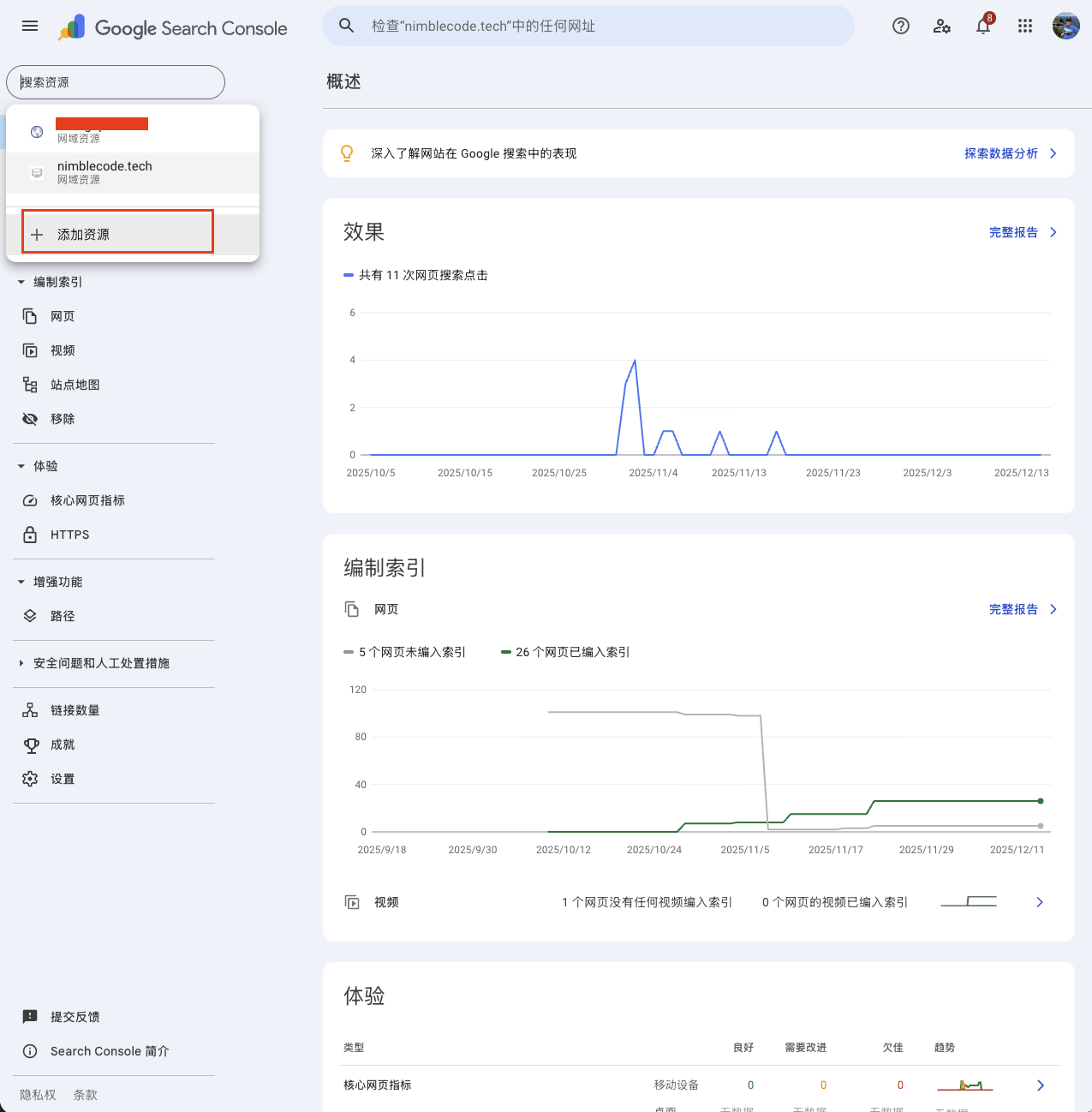
如果域名解析是在 GoDaddy 之类 Google Search Console 可以自动验证的网站,则添加流程与 2.1 相同。如果域名解析的网站不能被 Google Search Console 自动验证,则通过添加 TXT 记录也可以快速完成。下面以一个在阿里云解析域名的网站为例。
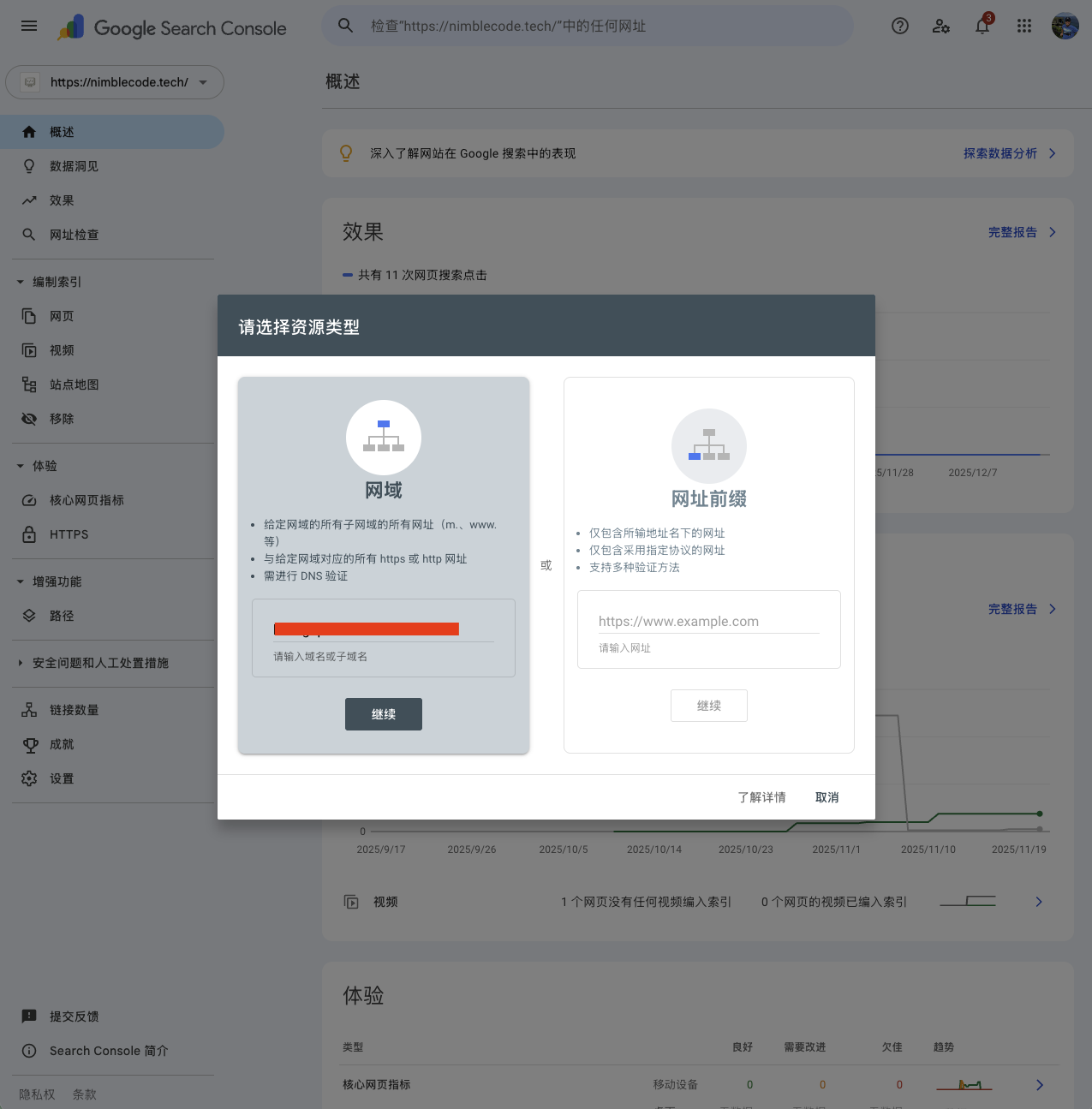
输入域名后,如果 Google Search Console 不能自动验证,则会显示手动验证的方法。默认推荐 TXT 记录。
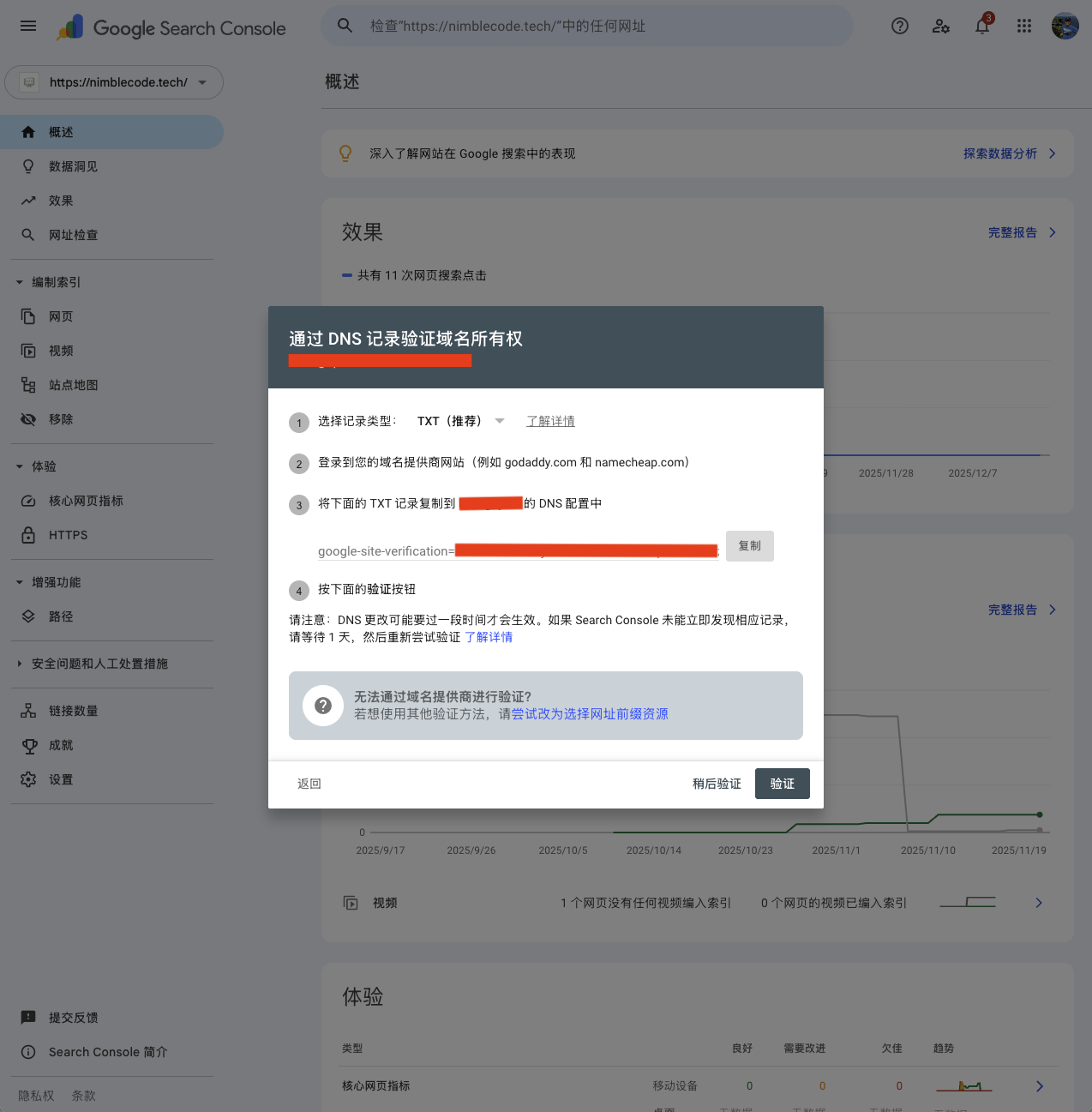
这里最重要的就是把 Google Search Console 提供的 TXT 记录值配置到目标域名的解析记录中去。以阿里云为例,登陆“云解析 DNS”产品的控制台后选择网站的域名,然后点击“添加记录”。这里“记录类型”选择 TXT,“主机记录”输入@,“记录值”填写 Google Search Console 提供的 TXT 记录值,最后“确定”保存即可。
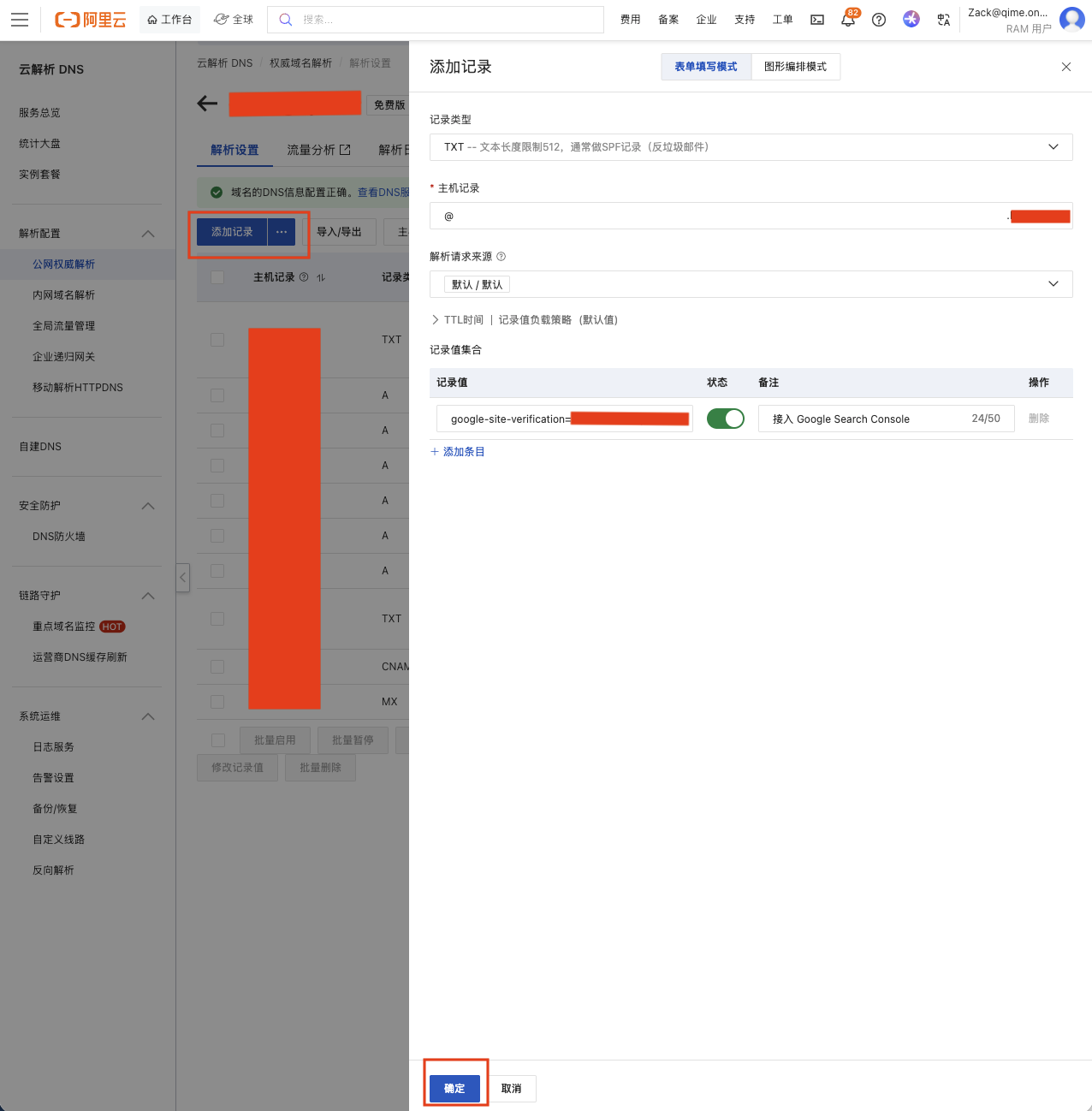
然后回到 Google Search Console 的导航页面,点击“验证”。
一般新的 TXT 记录很快就会生效。Google Search Console 验证通过后,就完成了新资源的添加。
3 常见问题与排查步骤
3.1 站点地图文件不存在或URL无法访问
这是最常见也最容易解决的问题。
造成该问题的原因一般是提交的URL链接错误,或者Hugo没有成功生成sitemap.map文件。
排查方法是在浏览器中直接访问之前提交的站点地图URL。
- 如果成功,应该能看到一个格式正确的XML文件内容;
- 如果失败,则需要检查Hugo项目public/目录下是否有sitemap.xml文件。如果没有,则要继续排查Hugo未生成该文件的原因。
3.2 服务器连接超时
造成该问题的原因一般是Googlebot无法连接到服务器,或者连接时间过长。例如服务器宕机、防火墙配置、服务器响应速度太慢等。
排查方法是使用工具(任何HTTP状态检测工具)来测试站点地图URL。如果是新部署的网站,可能是DNS更改尚未完全生效。
3.3 HTTP错误状态码
造成该问题的原因是服务器返回了错误状态码(例如4XX或5XX),而不是成功的200状态码。例如:
- 404 Not Found:站点地图文件路径错误(原因同3.1);
- 403 Forbidden或401 Unauthorized:服务器配置(例如防火墙规则)阻止了外部访问;
- 500 Server Error:服务器内部错误。
排查方法有两个:
- 在Google Search Console中,导航到“设置” -> “抓取统计信息”,查看Googlebot访问网站时是否有返回错误状态码;
- 或者使用Chrome的“开发者工具”的Network,查看访问站点地图时返回的HTTP状态码。
3.4 robots.txt阻止抓取
造成该问题的原因一般是robots.txt文件中的规则错误地禁止了Googlebot访问站点地图文件,甚至阻止了对整个网站的抓取。例如robots.txt文件中包含了类似
Disallow: /sitemap.xml
或
Disallow: /
这样的规则。
排查方法是在浏览器中访问站点的robots.txt文件,检查是否有以下情况:
- “User-agent: *”下是否有“Disallow: /”(禁止抓取整个网站);
- 是否有“Disallow: /sitemap.xml”(禁止抓取站点地图文件);
如果有这些情况,修正robots.txt文件后重新部署即可。
3.5 站点地图格式或大小问题
站点地图文件本身也可能存在XML格式错误,或者文件过大的问题。例如文件中存在无效字符、xml标签未正确闭合、编码错误等。当站点地图文件大小超过了Google的限制(未压缩前50MB),也会出现问题。
排查方法是使用Google Search Console的“网址检查”工具,输入站点地图URL。这样可以提供更详细的抓取错误信息。如果是因为站点地图文件过大,可以尝试将其分割为多个较小的文件。
4 总结
要将网站内容加入到Google搜索索引中,需要:
-
在Hugo中: 确保baseURL正确,并且已生成robots.txt和sitemap.xml。
-
在Google搜索引擎中: 将站点的sitemap.xml提交到Google Search Console。
完成这些步骤后,搜索引擎会开始抓取网站的新页面。抓取和索引过程可能需要几天到几周的时间。